ChatGPT · GDPR · modelli locali
ChatGPT e GDPR: quando puoi usare modelli cloud e quando serve davvero l'on premise.
Molte aziende partono da una scorciatoia sbagliata: “per la privacy ci serve un modello locale”. Il GDPR chiede controllo, non nostalgia per modelli piccoli e imprecisi.

Risposta breve
Puoi usare ChatGPT in azienda quando scegli un'offerta business o API governata, sai quali dati invii, hai una base giuridica, firmi o valuti il DPA, imposti accessi e retention, e documenti perché il rischio residuo è accettabile.
Ti serve un modello on premise quando non puoi inviare dati a un fornitore esterno neanche come responsabile del trattamento, quando un contratto lo vieta, quando lavori in ambienti air-gapped, quando la data residency non basta, o quando il valore dei dati rende inaccettabile qualunque dipendenza da cloud esterno.
La scelta seria non è “cloud cattivo, locale buono”. È: quale caso d'uso, quali dati, quale decisione, quale controllo?
L'errore: usare un modello locale scadente “perché GDPR”
Il problema si vede spesso. Un manager vuole usare AI su procedure, email, offerte, manuali o ticket. Qualcuno blocca tutto dicendo: “GDPR, quindi solo modello locale”. Poi l'azienda installa un modello debole, senza log seri, senza gestione accessi, senza DPIA, senza policy dati. Risultato: meno qualità e non più compliance.
Il GDPR non dice che devi usare modelli locali. Dice che devi trattare dati personali con liceità, correttezza, trasparenza, finalità definite, minimizzazione, sicurezza, conservazione limitata e accountability. Se usi un modello locale con dati personali, stai ancora trattando dati personali.
Il punto non è dove gira il modello. Il punto è chi vede i dati, per quale scopo, per quanto tempo, con quali misure, con quale contratto, con quale possibilità di audit e con quale impatto sulle persone.
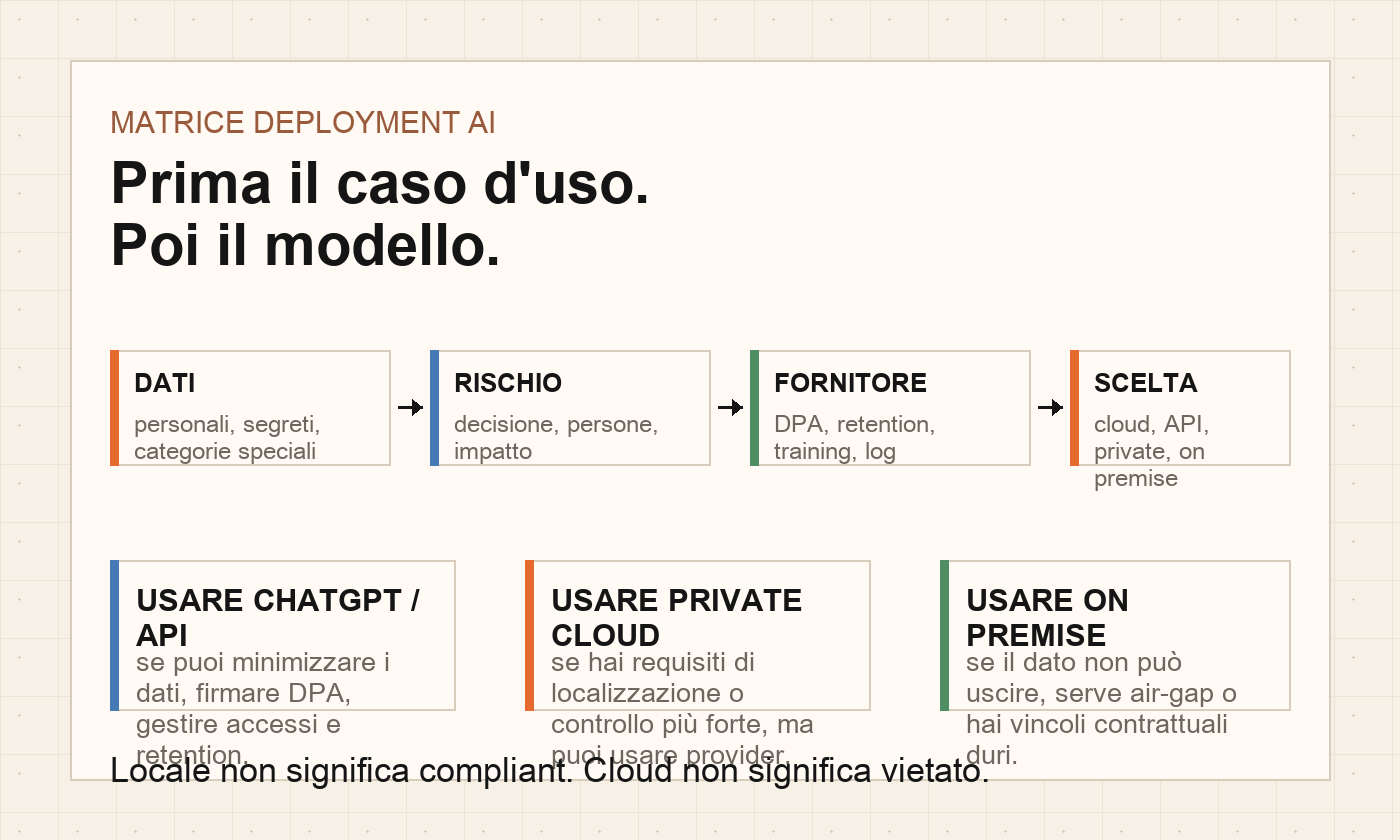
Quando puoi usare ChatGPT o API cloud
Per lavoro aziendale non partire dagli account personali dei dipendenti. Valuta ChatGPT Business, ChatGPT Enterprise o l'API Platform, perché lì puoi ragionare su workspace, accessi, DPA, retention, data residency e controlli amministrativi.
OpenAI dichiara che, di default, non usa input e output di ChatGPT Business, ChatGPT Enterprise, ChatGPT Edu, ChatGPT for Healthcare, ChatGPT for Teachers e API Platform per addestrare o migliorare i modelli. Per l'API, la documentazione indica che i dati non vengono usati per training salvo opt-in esplicito. Le offerte business supportano anche DPA e controlli di sicurezza; alcuni clienti idonei possono usare data residency e, per API o piani idonei, opzioni di elaborazione in regione.
| Caso d'uso | Cloud AI sensato quando | Controllo da scrivere |
|---|---|---|
| Bozze email, offerte, documenti commerciali | Riduci dati personali, usi workspace aziendale, vieti account personali. | Policy prompt, dati vietati, revisione umana prima dell'invio. |
| RAG su manuali, procedure, knowledge base | I documenti non contengono categorie speciali o segreti non condivisibili con il fornitore. | Access control, indicizzazione per permessi, log query, retention. |
| Supporto clienti con operatore umano | Il modello suggerisce risposte, ma un umano decide cosa inviare. | Informativa, minimizzazione ticket, escalation, storico conversazioni. |
| Analisi interna di processi e report | Puoi pseudonimizzare o aggregare dati prima dell'invio. | Dataset ammessi, mascheramento, owner, scadenza dati. |
| Agenti su CRM o ticketing | L'agente propone o prepara azioni, ma non modifica dati critici senza approvazione. | Permessi minimi, audit log, rollback, approvazione umana. |
Regola pratica: ChatGPT o API cloud sono candidati forti quando il valore del modello frontier conta più del controllo fisico dell'infrastruttura e quando puoi ridurre, contrattualizzare e monitorare il trattamento.
Quando serve davvero un modello on premise
L'on premise ha senso quando risolve un vincolo reale. Non quando serve a far sembrare prudente una decisione non analizzata.
Il dato non può uscire
Contratti cliente, norme settoriali, segreti industriali o obblighi interni vietano l'invio a provider esterni. In quel caso il cloud non è una discussione tecnica.
Serve air-gap o continuità offline
Fabbriche, laboratori, difesa, infrastrutture o reti separate possono richiedere inferenza locale per disponibilità, latenza o isolamento.
La pseudonimizzazione non basta
Dati sanitari, HR, minori, contenziosi, M&A, IP non pubblica o materiale strategico possono richiedere controllo più stretto, anche se il cloud ha buone garanzie.
Accetti il costo operativo
On premise significa patch, hardening, accessi, logging, backup, monitoraggio, incident response, valutazioni modello. Non è gratis e non è automaticamente più sicuro.
Se il modello locale risponde peggio, allucina di più o non segue istruzioni critiche, il rischio non sparisce. Cambia forma. In HR, compliance, sicurezza o customer care, un output peggiore può creare più rischio del provider cloud che volevi evitare.
Matrice decisionale: ChatGPT, API, private cloud o on premise
Usa questa matrice prima di comprare GPU, prima di bocciare ChatGPT e prima di promettere al cliente “tutto locale”.
| Scenario | Scelta probabile | Perché |
|---|---|---|
| Uso personale dei dipendenti su testi non sensibili | ChatGPT Business con policy interna | Serve governance più che infrastruttura dedicata. |
| Prodotto o workflow custom integrato nei sistemi | API Platform | Controlli input/output, logging applicativo, redazione dati, UX e permessi restano tuoi. |
| Dati UE con forte requisito di localizzazione | API o Enterprise con data residency idonea | Verifica disponibilità, endpoint supportati, retention e contratto. |
| Dati ad alto rischio ma condivisibili con responsabile esterno | Cloud governato più DPIA | Serve documentazione del rischio, non per forza modello locale. |
| Dati che non possono uscire dal perimetro | Private cloud o on premise | Il vincolo è sull'uscita del dato, non sulla moda tecnologica. |
| Ambiente senza rete o con latenza dura | On premise o edge | Disponibilità e latenza battono qualità del modello cloud. |
Controlli minimi prima della produzione
Se vuoi usare ChatGPT, API cloud o un modello locale, prepara la stessa scheda. Cambia il deployment, non cambia la responsabilità.

- Scrivi il caso d'uso. Input, output, utenti, decisione supportata, sistemi collegati.
- Classifica i dati. Dati personali, categorie particolari, dati clienti, segreti, IP, documenti contrattuali.
- Riduci prima di inviare. Pseudonimizza, maschera, aggrega o vieta alcune categorie di dato.
- Valuta il fornitore. DPA, sub-responsabili, retention, training, sicurezza, data residency, accessi admin.
- Fai screening DPIA. Se il trattamento può creare rischio elevato per le persone, fai DPIA prima del go-live.
- Metti un umano responsabile. Chi approva output, chi spegne il sistema, chi gestisce incidenti e reclami.
- Logga ciò che serve. Non tutto per sempre. Log sufficiente per audit, debugging e contestazioni.
- Riesamina. Ogni cambio di modello, dati, integrazione o finalità può cambiare la valutazione.
AI Act: il modello locale non basta
L'AI Act aggiunge un altro livello. Se il sistema entra in ambiti high-risk o incide su persone in contesti sensibili, devi ragionare su classificazione, istruzioni d'uso, logging, supervisione umana, trasparenza e, in alcuni casi, valutazione di impatto sui diritti fondamentali.
Un modello on premise usato per screening CV, scoring lavoratori, accesso a servizi essenziali o decisioni con effetti rilevanti non diventa innocuo perché gira nel tuo server. Devi dimostrare controllo del sistema e del processo.
FAQ su ChatGPT, GDPR e modelli locali
Posso usare ChatGPT Free, Plus o Pro per lavoro aziendale?
Per processi aziendali con dati reali, evita account personali non governati. Puoi disattivare alcune impostazioni di training lato consumer, ma per un'azienda servono workspace, policy, accessi, audit e contratto. Parti da Business, Enterprise o API.
Se OpenAI non fa training sui dati business, sono a posto?
No. È un punto importante, non la compliance completa. Devi valutare base giuridica, informativa, minimizzazione, retention, trasferimenti, sub-responsabili, sicurezza, diritti e rischio del caso d'uso.
Un modello locale elimina il problema dei trasferimenti extra UE?
Può eliminarlo solo se dati, log, backup, monitoring e persone che accedono al sistema restano nel perimetro previsto. Se usi servizi esterni per hosting, telemetry, supporto o labeling, il problema torna.
Quando basta pseudonimizzare i dati?
Basta quando il caso d'uso regge senza identità reali e il rischio residuo resta accettabile. Non basta se il contenuto permette di reidentificare persone o contiene segreti che non vuoi condividere.
La scelta migliore è sempre il modello più potente?
No. Il modello più potente conviene quando qualità, ragionamento e affidabilità cambiano il risultato. Se il vincolo vero è isolamento, latenza o controllo totale dei dati, puoi accettare un modello più piccolo, ma devi sapere cosa perdi.
Fonti e note
Fonti ufficiali consultate il 10 giugno 2026: OpenAI Enterprise Privacy, OpenAI Business data privacy, security, and compliance, OpenAI API data controls, OpenAI Data Processing Addendum, OpenAI data residency in Europe.
Fonti GDPR e AI Act: principi fondamentali del trattamento secondo il Garante, registro delle attività di trattamento, DPIA secondo il Garante, EDPB su privacy risks e LLM, AI Act articolo 6 high-risk, AI Act articolo 26 deployer.